Noticias
Estudio del MIT halla fallos de etiquetado en conjuntos de datos empleados para pruebas de IA
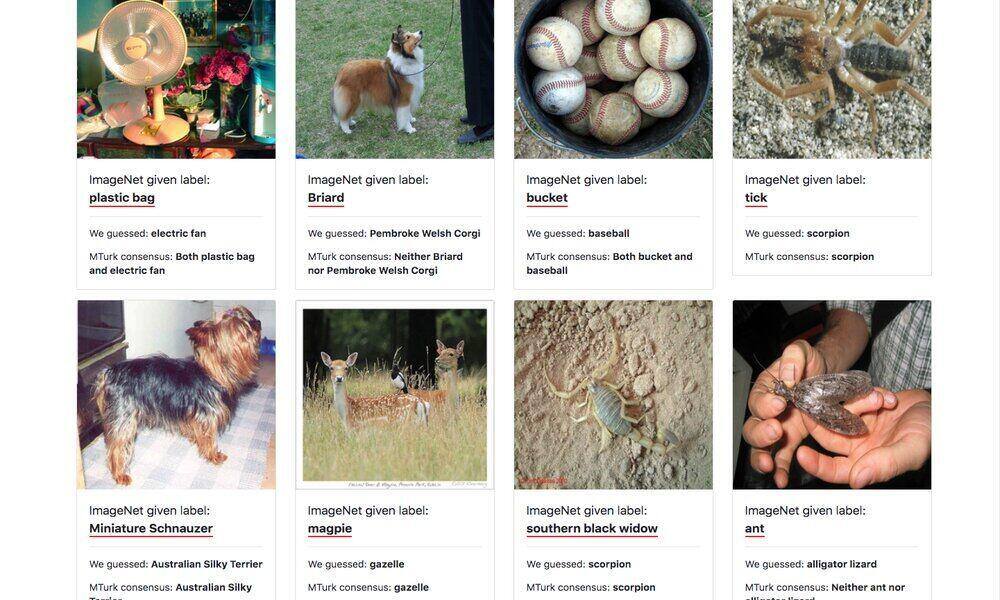
Un equipo de investigadores expertos en computación del MIT ha examinado 10 de los conjuntos de datos más citados para probar sistemas de machine learning, y a partir de los datos que han encontrado han elaborado un estudio en el que se demuestra que hay diversos fallos de etiquetado en parte de los datos que incluyen dichos conjuntos. En concreto, según VentureBeat, descubrieron que el 3,4% de los datos no estaba etiquetado o el que tenía no era del todo preciso.
Los conjuntos de datos, que además se han utilizado con bastante asiduidad, y han sido citados más de 100.000 veces, incluyen datos basados en texto procedentes de fuentes como grupos de noticias, Amazon e IMDb. Los errores se han producido por diversos motivos. Por ejemplo, opiniones de productos de Amazon que se etiquetan equivocadamente como positivas cuando en verdad son negativas, y al contrario.
Algunos de los errores, en el caso de los datos que tienen base en imágenes, se originan por mezclar especies de animales, y otros por etiquetar fotos mal utilizando objetos menos prominentes y dominantes en la foto. Por ejemplo, etiquetarlas con el nombre de un objeto secundario en vez de con el que más espacio ocupa en la imagen, esto es, con el principal.
En cuanto a los vídeos, se da el caso de que en uno de los conjuntos de datos compuesto por vídeos de YouTube, había un corte de una persona hablando a la cámara durante varios minutos y etiquetado como «campana de iglesia», aunque esta solo se oye unos segundos al final. Otro vídeo estaba etiquetado como orquesta aunque era un concierto de Bruce Springsteen.
Los investigadores emplearon un framework llamado confident learning para encontrar errores. Este framework se encarga de examinar conjuntos de datos para encontrar problemas o datos irrelevantes en etiquetas. Además, confirmaron los posibles errores a través de la plataforma de pequeñas tareas para freelances Mechanical Turk de Amazon. Así se encontraron los fallos, de media el porcentaje que hemos mencionado. El conjunto de datos con más fallos de los analizados fue el conocido como QuickDraw, una colección de imágenes mantenida por Google con alrededor de 5 millones, sobre el 10% de los datos. El que menos, ImageNet, con solo 2.900 errores de etiquetado.
El grupo que ha elaborado el informe ha puesto además en marcha una página web para que cualquiera que lo desee pueda comprobar que los errores encontrados son tales. Algunos son relativamente insignificantes. Otros son confusiones, sobre todo en imágenes. Otros son producto de matices e interpretaciones y no son importantes. Eso sí, aunque las etiquetas no tengan errores considerables, y solo sean pequeños fallos y matices, pueden llevar a consecuencias de cierto peso en sistemas de machine learning. Incluso aunque el fallo sea muy pequeño, puede derivar en que un sistema de Inteligencia Artificial sea capaz de diferenciar entre objetos que en apariencia sean muy distintos pero que se hayan contrastado con datos etiquetados de manera errónea.












InfoJobs compra Viterbit para acelerar en transformación tecnológica en recruiting

Anthropic acuerda pagar 1.500 millones a autores por usar sus libros sin permiso

Microsoft firma un acuerdo con Mistral para utilizar su infraestructura en Europa

Canonical lanza una tienda empresarial para Ubuntu Pro

Software de RRHH más avanzados gracias al uso de la IA

El precio de la memoria DDR5 alcanza otro récord histórico agravando la crisis del mercado tecnológico

LineShine: China supera a EE.UU alcanzando el primer puesto del TOP500 de supercomputadoras

OpenAI amplía su iniciativa de ciberseguridad Daybreak

Demandan a Samsung, SK Hynix y Micron por acordar mantener la escasez de RAM para subir precios

La economía digital crece hasta representar el 26% del PIB en 2026

Akrites, la iniciativa de la Fundación Linux para detección de vulnerabilidades

La IA frente al espejo
InfoJobs compra Viterbit para acelerar en transformación tecnológica en recruiting

Cloudflare desarrollará un protocolo de Internet centrado en privacidad con Chrome, Firefox y Edge

Meta anuncia el cambio de liderazgo en WhatsApp

IONOS y Q.ANT impulsarán la computación fotónica en el marco de la soberanía europea en IA

MuyPymes lanza Easy&Smart 2026

Oracle ha eliminado 21.000 puestos de trabajo en los últimos 12 meses
-

 NoticiasHace 5 días
NoticiasHace 5 díasEl comercio electrónico, en el punto de mira de los ataques de bots de IA y del fraude automatizado en 2026
-

 NoticiasHace 3 días
NoticiasHace 3 díasNokia presenta su plataforma comercial AI-RAN
-

 NoticiasHace 5 días
NoticiasHace 5 díasEl Gobierno invierte 1,92 millones en Kaleidos, empresa creadora de Penpot
-

 NoticiasHace 2 días
NoticiasHace 2 díasEuropa avanzará en soberanía tecnológica para 2030, pero seguirá por detrás de China y EEUU