A Fondo
SubQ: la revolución que promete romper el coste de la IA empresarial

Estos últimos meses han sido muy movidos con los avances de la IA y sus consecuencias para el panorama tecnológico de consumo y empresarial. Una revolución que ha visto cómo los agentes ocupaban el foco principal pero sin restar importancia a una carrera incansable por parte de sus principales actores para presentar modelos cada vez más potentes. Y la idea central de estos anuncios es siempre la misma: más datos, más parámetros, más cómputo, más entrenamiento y más infraestructura. Simplificando: más prestaciones aplicando fuerza bruta. Ese enfoque ha producido sistemas cada vez más capaces, pero también ha consolidado una arquitectura cara, difícil de auditar y concentrada en un número reducido de compañías con acceso a capital, talento, chips y centros de datos a una escala que pocos competidores pueden igualar.
En paralelo, empieza a tomar forma una segunda vía. Nuevas empresas de IA están intentando competir no solo con modelos más grandes, sino con diseños distintos: arquitecturas más eficientes, modelos especializados, sistemas de contexto largo, nuevas formas de memoria, agentes de código, herramientas de búsqueda profunda y aproximaciones que cuestionan algunos supuestos del Transformer clásico. Su promesa no consiste únicamente en mejorar la calidad de las respuestas, sino en cambiar una economía de uso de la IA que empieza a amenazar con poner obstáculos a la adopción generalizada por parte de las empresas.

En este contexto la empresa Subquadratic ha publicado un anuncio que ha hecho levantar muchas cejas de responsables de tecnología inmersos en la economía del token. Y es que han mostrado cifras de rendimiento que, si se verifican de forma independiente, reducirían el coste y la complejidad de la IA empresarial de forma significativa. El equipo tiene credenciales reales, el problema que atacan existe y los 29 millones de financiación semilla vienen de inversores con historial. Lo que falta es el informe técnico completo y la validación externa.
El 5 de mayo de 2026, Subquadratic salió del modo stealth y presentó SubQ, su primer modelo de lenguaje, con una afirmación central: haber desarrollado una arquitectura de atención para modelos frontier que, según la empresa, escapa al límite cuadrático que define y restringe todos los grandes modelos de lenguaje desde 2017. La reacción en foros de investigación fue inmediata y polarizada.
Parte de la comunidad técnica recibió el anuncio con interés genuino porque el problema de fondo es real y el enfoque tiene base matemática documentada. Otra parte señaló que los datos proceden casi en su totalidad de la propia empresa, que la model card completa está pendiente y que el modelo disponible hoy en la API no es el de 12 millones de tokens que encabeza todos los titulares. El lanzamiento incluye tres productos en beta privada: una API de contexto largo para desarrolladores y empresas, SubQ Code, un agente de programación accesible desde línea de comandos, y SubQ Search, una herramienta de búsqueda orientada a investigación.
Un límite real y costoso
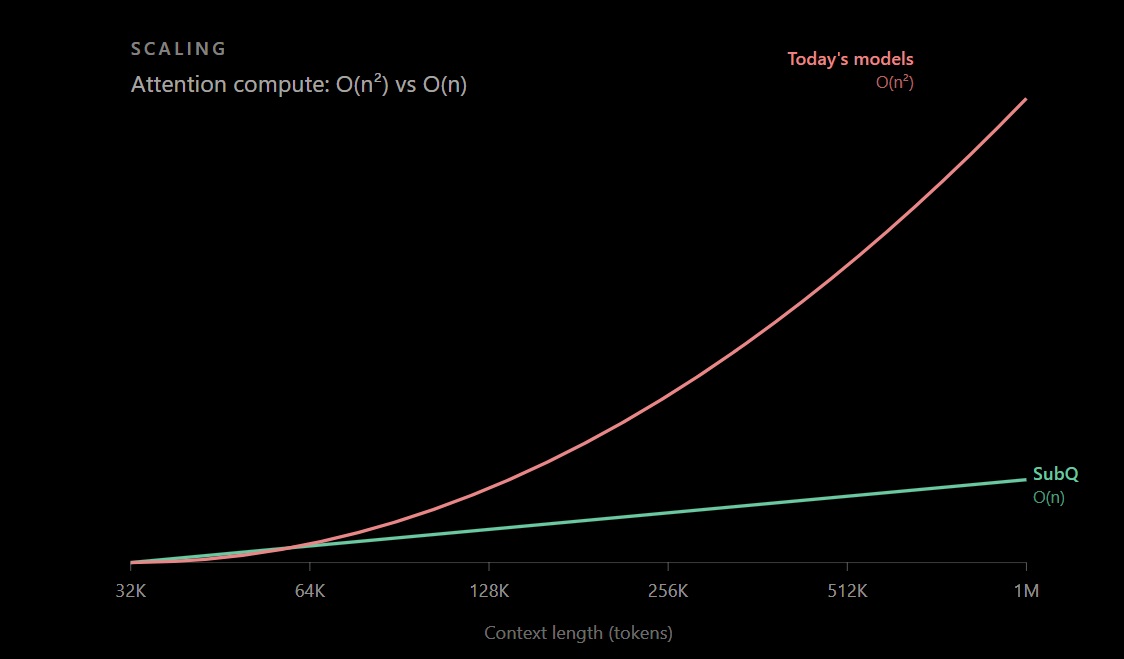
Los Transformers han permitido el desarrollo de todos los grandes modelos de lenguaje modernos porque permite procesar secuencias completas en paralelo, superando la lentitud de los modelos antiguos que leían palabra por palabra. Sin embargo su mecanismo de atención encarece el procesamiento de forma no lineal a medida que crece el contexto. Para empresas que quieren usar IA sobre grandes volúmenes de información, esa limitación afecta directamente al coste de cada consulta, a la latencia del sistema y a la complejidad de la arquitectura que deben construir para compensarla.
Desde la publicación del paper Attention Is All You Need en 2017, el Transformer se ha convertido en la arquitectura dominante. Su mecanismo de atención densa compara cada elemento del texto con todos los demás para decidir qué partes son relevantes entre sí. El coste de ese proceso crece de forma cuadrática con la fórmula O(n²). El paper de FlashAttention, una de las optimizaciones más importantes para acelerar la atención exacta, parte precisamente de ahí: los Transformers son lentos y consumen mucha memoria en secuencias largas porque la autoatención tiene complejidad temporal y de memoria cuadrática respecto a la longitud de la secuencia.

En la práctica corporativa, ese comportamiento se traduce en una dificultad concreta. Analizar un contrato extenso, un expediente completo o un repositorio de código puede resultar caro o lento si se envía directamente al modelo. Por eso muchas organizaciones construyen sistemas RAG que fragmentan la información, recuperan los pasajes más relevantes mediante búsqueda semántica y solo envían una parte al modelo. El RAG funciona, pero añade procesos complejos pues hay que fragmentar documentos, crear y mantener bases vectoriales, gestionar permisos, actualizar información y evaluar continuamente si los fragmentos recuperados son los adecuados. Cuando esos sistemas crecen, crecen también los costes de mantenimiento y los puntos de fallo.
Subquadratic añade una crítica específica a estos sistemas de recuperación: al fragmentar documentos, puede perderse la posición, la jerarquía y el contexto cercano que dan sentido a un fragmento. Una parte de un texto puede contener las palabras correctas y aun así haber perdido la razón por la que ese texto importa dentro del documento completo. En flujos con varios agentes encadenados, los errores se acumulan entre pasos y el contexto se comprime de forma repetida.
El trabajo Lost in the Middle añade otro matiz importante ya que algunos modelos de contexto largo rinden mejor cuando la información relevante aparece al principio o al final del prompt, y peor cuando aparece en posiciones intermedias. Dicho de otro modo, contexto nominal, la cantidad de tokens que el modelo acepta técnicamente, y contexto funcional, la cantidad de información que puede usar con precisión real, son dos cifras distintas que pocas veces coinciden.
Qué propone SSA de Subquadratic
Subquadratic afirma que su arquitectura SSA reduce el coste de la atención porque el modelo selecciona qué partes del contexto debe comparar en cada operación, en lugar de calcular todas las combinaciones posibles entre tokens. Si ese principio funciona a escala de producción tal como describen sus autores, el coste de inferencia en tareas de contexto largo caería de forma estructural, no marginal.
La compañía denomina su enfoque SSA (Subquadratic Sparse Attention o Subquadratic Selective Attention), según la propia documentación. La idea central es que el modelo aprende a identificar qué posiciones del contexto son relevantes para cada operación y calcula atención exacta solo sobre esas posiciones seleccionadas. La diferencia con respecto a los enfoques habituales de atención eficiente está en que esa selección depende del contenido, no de un patrón fijo de ventana local o de bloques predefinidos. Subquadratic sostiene que SSA puede elegir relaciones relevantes en cualquier parte del contexto, independientemente de su posición, y que el coste crece con el número de posiciones seleccionadas, no con todas las combinaciones posibles entre tokens.
La empresa sitúa SSA frente a varios enfoques alternativos y concluye que la atención dispersa de patrón fijo puede perder información si esta queda fuera del patrón elegido, los modelos recurrentes o de espacio de estados comprimen la secuencia en un estado de capacidad limitada, las arquitecturas híbridas conservan capas densas que encarecen el sistema a medida que crece el contexto y DeepSeek Sparse Attention traslada parte del coste a un indexador que según Subquadratic, mantiene escalado cuadrático. Son comparaciones que tienen sentido pero proceden de la propia empresa y deberán contrastarse con evaluaciones externas cuando el informe técnico completo esté disponible.
Velocidad, entrenamiento y benchmarks
El segundo post técnico de Subquadratic añade un detalle que cambia la lectura del mensaje comercial, la cifra de mejora de 1.000 veces no corresponde al modelo disponible en la API. Corresponde a un resultado de investigación a 12 millones de tokens. Los números publicados para el modelo en producción son distintos, aunque siguen siendo llamativos.
En velocidad de procesamiento de entrada, Subquadratic compara SSA con atención densa usando FlashAttention-2 en GPUs B200 y publica mejoras de 7,2 veces a 128.000 tokens, 13,2 veces a 256.000 tokens, 23 veces a 512.000 tokens y 52,2 veces a un millón de tokens. A un millón de tokens, la empresa afirma que SSA reduce los FLOP de atención 62,5 veces frente a la atención cuadrática estándar. Esa es la cifra relevante para el modelo actualmente en acceso anticipado, no la de 1.000 veces que aparece en los titulares.
El entrenamiento de SubQ sigue tres fases: preentrenamiento para establecer capacidad lingüística y representaciones de contexto largo, ajuste supervisado para seguimiento de instrucciones, razonamiento estructurado y generación de código, y aprendizaje por refuerzo orientado a recuperación fiable en contexto largo. Este tercer paso tiene importancia práctica porque una arquitectura eficiente no garantiza por sí sola que el modelo use bien la información que recibe. Un modelo puede aceptar mucho contexto y aun así responder priorizando lo que aparece cerca del principio o del final. Subquadratic afirma que su fase de aprendizaje por refuerzo está diseñada para reducir ese tipo de fallos, aunque los benchmarks generales que lo demostrarían llegarán con la model card completa, todavía sin fecha confirmada.

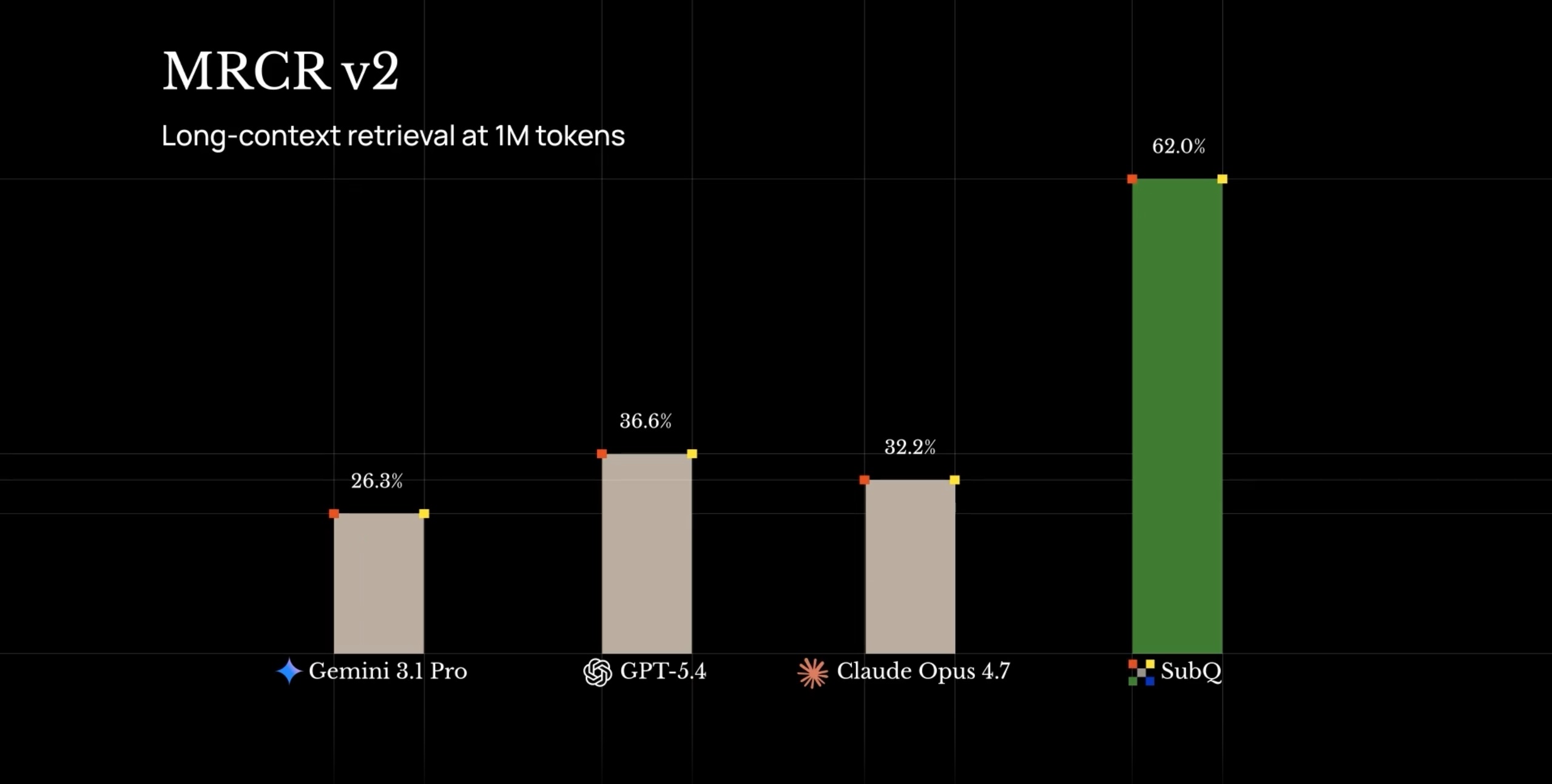
Los resultados publicados se concentran en dos ejes. En RULER a 128.000 tokens, SubQ obtiene un 95%, frente al 94,8% que la empresa atribuye a Claude Opus 4.6, con un coste de 8 dólares frente a los aproximadamente 2.600 dólares de Opus en la misma prueba, según recoge el análisis de SiliconANGLE. En MRCR v2, una prueba diseñada para medir la recuperación e integración de varias piezas de evidencia distribuidas en contextos largos, SubQ aparece con un 65,9%, por debajo de los 78,3% de Opus 4.6 y del 74% de GPT-5.5 según la propia tabla de Subquadratic. En SWE-Bench Verified, que evalúa capacidad de ingeniería de software sobre incidencias reales de GitHub, SubQ publica un 81,8%, frente al 80,8% de Opus 4.6 y el 87,6% de Opus 4.7. El dato de MRCR v2 merece atención porque es precisamente en recuperación distribuida donde la propuesta de contexto masivo debería demostrar más ventaja, y en ese benchmark SubQ no lidera.
Fact check del anuncio de SubQ
Un anuncio como este que promete revolucionar la economía del token actual ha creado suspicacias por la falta de pruebas tangibles de lo que se está anunciando. Lo primero es lo primero: Subquadratic es una empresa real, con equipo verificable y financiación respaldada por inversores con historial. Las señales de alerta no cuestionan su legitimidad como empresa, cuestionan la correspondencia entre lo que anuncia en sus materiales de marketing y lo que el producto disponible hoy puede demostrar.
La más visible es la brecha entre el titular y el modelo en producción. Todos los materiales de Subquadratic enfatizan la ventana de 12 millones de tokens, pero el modelo que se puede solicitar vía API en acceso anticipado es SubQ 1M-Preview, con una ventana de un millón de tokens. Los 12 millones son un resultado de investigación en laboratorio, no una capacidad comercial disponible.
La fecha de llegada a producción no está confirmada. La fecha no aparece destacada en la comunicación de la compañía, y la comunidad técnica la ha señalado como la contradicción más directa del lanzamiento, recogida en los debates activos en Reddit sobre el patrón de promesas de ventana de contexto incumplidas en el sector.
La segunda señal es el estado de la documentación. El informe técnico completo figura como coming soon en la web de la empresa, aunque en algunos post de X de Alex Whedon habla de materiales adicionales la próxima semana. Sin ese documento y sin acceso a los pesos del modelo, los benchmarks publicados tienen el estatus de datos comunicados por la compañía, no de resultados verificables de forma independiente. Subquadratic indica que algunos resultados fueron verificados por un tercero, pero no especifica quién ni bajo qué condiciones. El precedente más citado en foros técnicos es el de Magic.dev: en 2024 anunció un modelo con ventana de 100 millones de tokens y una ventaja de eficiencia de 1.000 veces, captó más de 500 millones de dólares y, a principios de 2026, no existe evidencia pública de uso externo de su modelo LTM-2-mini.

A esta cautela se suma una aclaración posterior de Alexander Whedon en la que afirma que SubQ utiliza pesos de modelos open source como punto de partida, una decisión que el CTO atribuye a la etapa de financiación y madurez de la compañía. Esa aclaración no invalida la propuesta de SSA, pero sí obliga a matizar la lectura de expresiones como “construido desde cero” o “primer modelo frontier”: lo que Subquadratic reivindica como diferencial es la arquitectura de atención y el proceso posterior de adaptación, no necesariamente el entrenamiento completo del modelo comercial desde cero.
La tercera señal es la concentración de benchmarks en los ejes donde SSA tiene ventaja estructural. RULER, MRCR v2 y SWE-Bench Verified son pruebas relevantes, especialmente para contexto largo y programación, pero los resultados en razonamiento general, matemáticas, multilingüe, robustez, seguimiento de instrucciones o resistencia a inyección de prompt llegarán con la model card completa. Hasta entonces, la comparativa frente a modelos frontier en uso corporativo real permanece abierta.
Hay que decir que Whedon ha estado muy activo en redes contestando a muchas de las dudas que se han planteado sobre el proyecto y ha publicado varias aclaraciones que conviene incorporar a la lectura del lanzamiento. La más importante es que SubQ parte de pesos de modelos open source, que después se portan a la nueva arquitectura y se someten a CPT, SFT y RL, según explicó en respuesta a Will Depue. En otra respuesta, Whedon calificó como un error de comunicación del equipo la idea de que el modelo comercial actual haya sido entrenado íntegramente desde cero, aunque sostuvo que la compañía sí ha hecho experimentos desde cero a menor escala y que esa es su intención con más financiación.
También defendió la comparación con FlashAttention porque, según su respuesta a Jas Oberoi, buscaba mostrar una mejora implementada en velocidad real y no solo una reducción teórica de FLOP. Estas aclaraciones hacen más precisa la fotografía del proyecto y reducen parte de la ambigüedad técnica, pero también confirman que la comunicación inicial mezcló resultados de laboratorio, producto disponible y objetivos futuros que deben evaluarse por separado. Por otro lado parece claro que no se esconden a la hora de defender el proyecto…
La apuesta paralela de LeCun
Hablando de propuestas alternativas Yann LeCun, Premio Turing 2018 y fundador del laboratorio FAIR de Meta, trabaja en un horizonte diferente con AMI Labs, una startup parisina centrada en modelos capaces de razonar y planificar sobre representaciones del mundo físico, más allá de la predicción de texto. Según Reuters, AMI ha captado 1.030 millones de dólares a una valoración pre-money de 3.500 millones, con inversores como Bezos Expeditions, NVIDIA, Toyota Ventures y Eric Schmidt.

Su arquitectura JEPA (Joint Embedding Predictive Architecture) predice en espacios de representación abstracta en lugar de generar contenido token a token, un enfoque con implicaciones directas en sectores regulados bajo NIS2 o DORA donde las alucinaciones tienen consecuencias clínicas o legales. Para un CIO, la diferencia temporal con SubQ es determinante: AMI Labs opera hoy como un laboratorio de investigación fundamental y, como reconoce el propio CEO Alexandre LeBrun, no generará ingresos a corto plazo. SubQ puede evaluarse en un piloto esta semana (supuestamente). AMI no.
Hoja de ruta para el CIO
Parece claro que cualquier empresa que esté experimentando o poniendo en producción proyectos basados en IA utilizando LLMs debería como mínimo prestar atención y posiblemente poner a prueba la propuesta de Subquadratic ya que puede suponer un cambio radical en lo que respecta a costes. Pero antes de evaluar SubQ, conviene auditar dónde la organización está pagando hoy el coste de la limitación de contexto: pipelines de RAG complejos, vectorización masiva, fragmentación manual de documentos, agentes encadenados con recuperación frágil o llamadas repetidas a modelos caros.
Sin esa línea base, cualquier promesa de ahorro será difícil de medir con criterio propio. El siguiente movimiento es seleccionar uno o dos casos de uso donde el contexto largo sea la limitación principal real, un repositorio de código, un expediente legal con anexos, un conjunto de contratos relacionados, y medir SubQ 1M-Preview contra el sistema actual con métricas definidas antes del experimento y no después: precisión, coste por tarea resuelta, latencia, trazabilidad de la respuesta, tasa de errores graves y esfuerzo de integración.
El modelo disponible hoy es el de un millón de tokens; evaluar ese, no el de 12 millones que aparece en el marketing. Cualquier decisión de arquitectura a largo plazo debe condicionarse a tres hitos que aún no existen: publicación del informe técnico completo, evaluación independiente reproducible y disponibilidad comercial confirmada de la ventana de 12 millones de tokens. En el mercado de IA de 2026, donde las promesas de ventana de contexto se han convertido en un género propio, distinguir entre lo que una empresa puede demostrar hoy y lo que anuncia para el futuro es una competencia crítica..














Oracle ha eliminado 21.000 puestos de trabajo en los últimos 12 meses

MuyPymes lanza Easy&Smart 2026

IONOS y Q.ANT impulsarán la computación fotónica en el marco de la soberanía europea en IA

Meta anuncia el cambio de liderazgo en WhatsApp

Cloudflare desarrollará un protocolo de Internet centrado en privacidad con Chrome, Firefox y Edge

OpenAI amplía su iniciativa de ciberseguridad Daybreak

La UE presenta por fin sus planes para despegar en soberanía tecnológica

«Las empresas no empiezan por la infraestructura, sino por los retos del negocio»

Ideas para desarrollar un software de RR.HH con vibe coding

El Gobierno aprueba el proyecto de su Ley de IA

Protagonistas invisibles: la cara oculta de la inteligencia artificial

Casos de éxito de transformación digital con IA de empresas TIC y Big Tech
Oracle ha eliminado 21.000 puestos de trabajo en los últimos 12 meses

Primeros resultados del Proyecto Glasswing: asegurar la IA con IA, funciona
Ideas para desarrollar un software de RR.HH con vibe coding

Huawei presenta su solución de infraestructura de datos para centros de datos de IA

ASUS incluye IA híbrida en sus dispositivos comerciales

Guerra de precios en la IA: DeepSeek reduce la tarifa de su modelo V4?Pro AI un 75%
-
 NoticiasHace 6 días
NoticiasHace 6 díasSynology lanza DiskStation Manager 7.4
-

 NoticiasHace 7 días
NoticiasHace 7 díasEl Gobierno destina 719 millones a un proyecto español de desarrollo de una gigafactoría de IA
-

 NoticiasHace 5 días
NoticiasHace 5 díasEl nuevo HP EliteBook X G2i: menos de un Kg procesamiento neuronal y pantalla OLED
-

 NoticiasHace 5 días
NoticiasHace 5 díasMayoría de empresas de EMEA no saben de qué proveedores, modelos e infraestructura de IA dependen