A Fondo
TurboQuant de Google, el caché KV y el nuevo paradigma de la eficiencia en IA

La era de la experimentación ha terminado, como apuntaba Satya Nadella en su visita a Madrid la IA tiene que demostrar su rentabilidad. Lo que queda es una realidad sin margen para la ambigüedad: en 2026, el gasto en infraestructura de IA de los cinco grandes hiperescalares (Microsoft, Google, Amazon, Meta y Apple) alcanzará los 700.000 millones de dólares, una cifra que equivale al PIB completo de economías como Argentina o Suecia. Al mismo tiempo, la Agencia Internacional de la Energía (IEA) estima que el consumo eléctrico de los centros de datos se duplicará antes de 2030, superando los 1.000 TWh, el equivalente a toda la demanda eléctrica de Japón. En ese contexto, la inferencia (el acto de poner los modelos a trabajar para usuarios reales, no entrenarlos) ya representa entre el 80% y el 90% del coste total del ciclo de vida de la IA. Cada token generado arrastre un coste de ineficiencia derivado de una gestión de memoria que no ha evolucionado al mismo ritmo que los modelos. Y el origen de ese impuesto tiene nombre concreto: el caché KV.
Hace muchos años (en términos relativos) la optimización del software era un mantra importantísimo que llevaba empresas enteras a la quiebra y que marcaban la diferencia entre un producto usable y que no lo era. Ahora que la IA está poniendo en jaque la idea de que los recursos hardware parezcan casi ilimitados, la optimización empieza a volver a estar de moda. El caché KV (Key-Value cache) es la memoria temporal que un LLM necesita para no releer el contexto completo de una conversación en cada respuesta. Es invisible para el usuario final, pero se ha convertido en uno de los cuellos de botella que más influyen en la concurrencia, el coste por interacción y la rentabilidad de un despliegue en producción. La confluencia de varios anuncios recientes, liderados por TurboQuant de Google Research, está empezando a cambiar este cálculo.
El coste real del caché KV
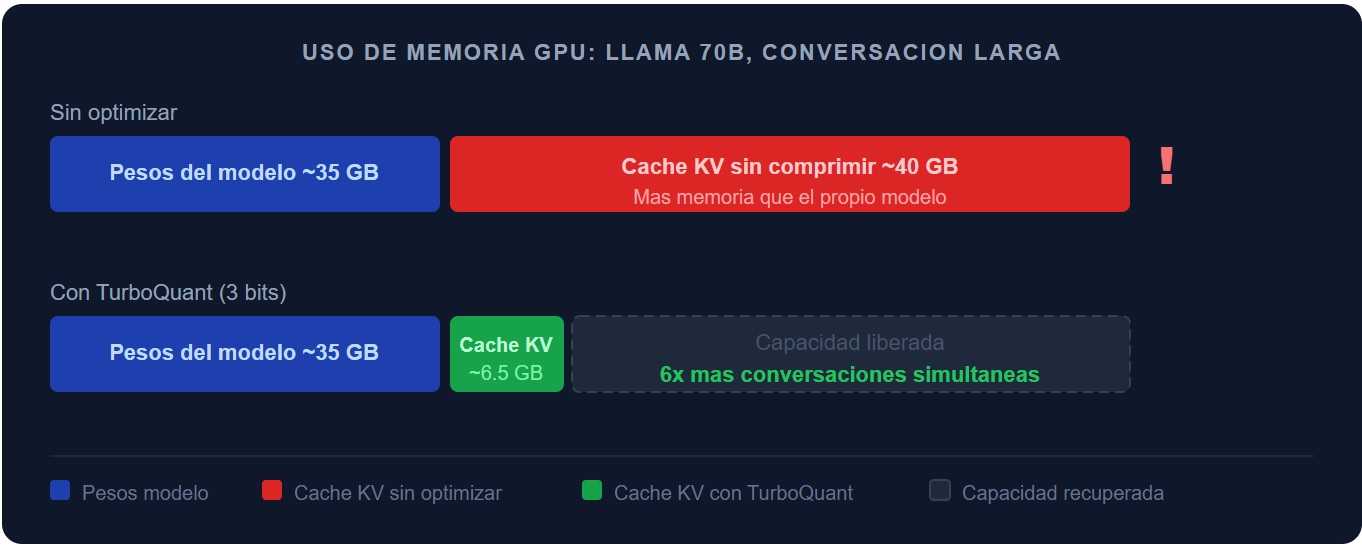
En configuraciones de contexto largo para modelos como Llama 70B, el caché KV puede acercarse a decenas de GB de memoria GPU y, en ciertos escenarios, superar la memoria ocupada por los pesos del modelo. En escenarios de contexto muy largo, una fracción sustancial de una NVidia H100 puede quedar ocupada simplemente por el historial necesario para servir a un usuario. Con tasas de cómputo en nube de entre 2 y 3 dólares por hora por GPU H100, la rentabilidad de muchos despliegues empieza a jugarse precisamente en este punto.
El status quo del mercado, recogido en el análisis de Gartner sobre infraestructura IA optimizada, ha abordado este problema con soluciones parciales: cuantización uniforme de pesos, offloading a memoria del sistema o simplemente adquirir más hardware. Ninguna de estas vías ataca el problema de fondo a través de la optimización. La ineficiencia en este punto no es un detalle técnico: es un problema de gasto de capital con impacto directo en el coste total de propiedad de cualquier iniciativa de IA empresarial, sobre todo cuando se empiecen a repercutir los costes reales a los usuarios de los modelos.
El espejismo de los precios actuales
La guerra de precios de 2024 y 2025 ha dificultado leer con claridad el coste real de la IA en producción. Según el Stanford HAI AI Index 2026, para que la inferencia de modelos de clase frontera sea sostenible con márgenes operativos del 60-70%, el precio de mercado apunta a que, para sostener determinados márgenes operativos, los precios de mercado tendrían que converger hacia niveles muy bajos por cada 1.000 tokens. A ese precio, una empresa con un volumen mensual de 1.000 millones de tokens (equivalente a un servicio de soporte técnico automatizado de escala media) afronta un gasto fijo de 10.000 dólares mensuales en consumo de API. Es una cifra manejable.
Lo que no es manejable es el escenario alternativo: ese mismo volumen sobre infraestructura propia sin optimización de caché KV escala hasta los 0,15 dólares por cada 1.000 tokens, según los modelos de coste de inferencia de SemiAnalysis, debido a la infrautilización crónica del hardware cuando la memoria GPU se fragmenta entre pesos del modelo y caché sin comprimir. El resultado es una factura mensual de 150.000 dólares por exactamente el mismo nivel de servicio. La diferencia entre ambos escenarios no la determina el proveedor de modelo ni el contrato de nube: la determina si el equipo de infraestructura ha optimizado o no la gestión del caché KV. La optimización de memoria ya no puede tratarse solo como una decisión técnica: también es una decisión financiera.
Tres bits, casi sin pérdidas
TurboQuant, desarrollado por el equipo de Vahab Mirrokni (VP y Google Fellow en Google Research) junto a Amir Zandieh y colaboradores de KAIST y NYU, será presentado en ICLR 2026 y representa el avance más significativo en compresión de caché KV de los últimos tres años. La propuesta es concreta: comprimir el caché KV a 3 bits por valor con una reducción de memoria mínima del 6x y sin degradación apreciable en ninguno de los cinco benchmarks de contexto largo evaluados (LongBench, Needle In A Haystack, ZeroSCROLLS, RULER y L-Eval).
El mecanismo técnico puede resumirse en dos fases con impacto claro desde el punto de vista del negocio. Primero, PolarQuant convierte los vectores de datos a coordenadas polares, eliminando el overhead de memoria que acarrean los métodos tradicionales de cuantización (ese overhead son los parámetros extra que los métodos convencionales necesitan almacenar para saber «cómo descomprimir», lo que anula parte del beneficio de comprimir). Segundo, QJL (Quantized Johnson-Lindenstrauss) aplica un verificador matemático de errores de 1 bit sobre el residual, garantizando estimaciones de producto interno sin sesgo. No requiere reentrenamiento del modelo, no exige fine-tuning, es un reemplazo directo: los kernels de GPU (las instrucciones de bajo nivel que controlan el chip, escritos en lenguajes como CUDA o Triton) ejecutan la descompresión directamente en los registros internos de la GPU, eliminando el retraso que lastraba a métodos anteriores y que es precisamente lo que hace posible el salto de hasta 8 veces en velocidad de cómputo.
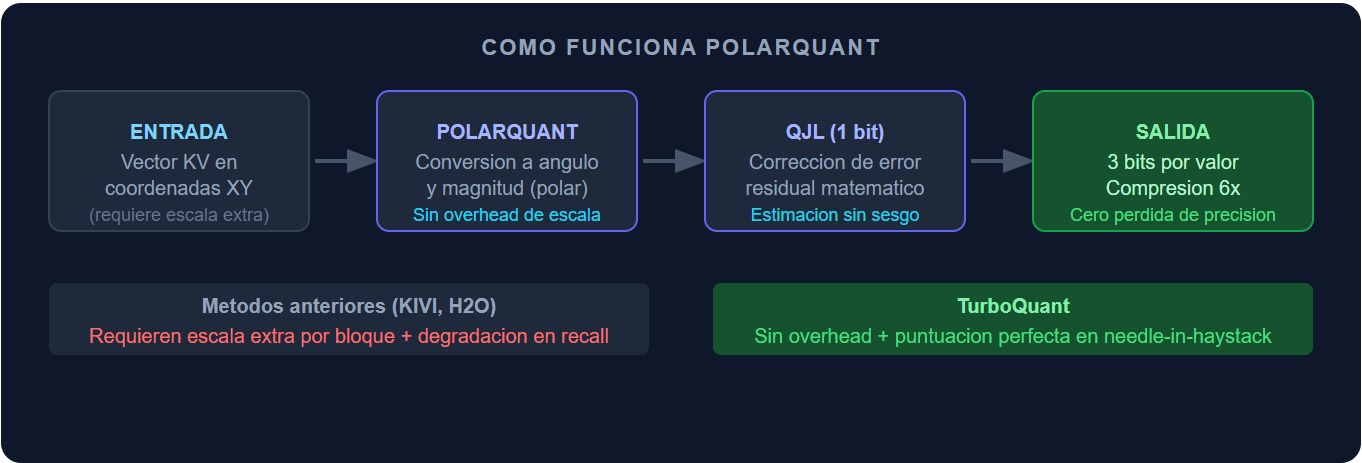
El contraste con el predecesor de referencia en el campo, KIVI (2-bit KV Cache), es revelador: KIVI demostró que bajar a 2 bits era viable, pero introducía degradación en tareas de recuperación precisa. TurboQuant a 3 bits supera a KIVI en recall (capacidad de recuperar información específica) mientras mantiene puntuaciones perfectas en las pruebas «needle-in-a-haystack». Para un CIO, esto se traduce en un dato operativo de primer orden: en teoría, y dependiendo del patrón de carga el mismo hardware puede atender aproximadamente 6 veces más conversaciones simultáneas, o mantener ventanas de contexto 6 veces más largas, o una combinación de ambas, sin adquirir un solo servidor adicional.
Por qué no es solo investigación teórica
El argumento más potente de TurboQuant es su naturaleza agnóstica al modelo. Fue validado sobre Llama, Gemma y Mistral, los tres modelos de código abierto más desplegados en entornos empresariales según los rankings de Hugging Face. Adicionalmente, Google señala que su aplicación al problema de búsqueda vectorial (la tecnología que permite a los motores de búsqueda encontrar resultados similares entre miles de millones de entradas) supera a los métodos actuales, incluyendo Product Quantization. Para organizaciones con arquitecturas RAG (Retrieval-Augmented Generation, modelos de IA que consultan bases de datos propias) desplegadas o en hoja de ruta, TurboQuant aplica en dos frentes simultáneamente.
Pero la optimización para seguir alimentando el leviatán de la IA ha ido siguiendo otros caminos, algunos que cuestionan el planteamiento de base de los modelos de LLM.
Cuantización nativa en hardware
Mientras Google optimiza en el plano algorítmico, NVIDIA ha llevado la cuantización al nivel de la arquitectura hardware con NVFP4, disponible de forma nativa en la plataforma Blackwell y Blackwell Ultra. El formato NVFP4 aplica un escalado en dos niveles: un factor de escala E4M3 por cada bloque de 16 valores, más un escalar FP32 de nivel tensorial. Esta arquitectura reduce el error de cuantización respecto al formato MXFP4 de generaciones anteriores (que agrupaba 32 valores), lo que se traduce en una degradación de precisión inferior al 1% en benchmarks clave de generación de código y tareas de contexto largo.

El impacto operativo es cuantificable: NVFP4 reduce la huella de memoria del modelo en aproximadamente 3,5 veces respecto a FP16 (el formato estándar de alta precisión), y en 1,8 veces respecto a FP8. Las GPUs Blackwell Ultra no solo procesan más rápido gracias al NVFP4: su ancho de banda de memoria HBM3e (la memoria de alta velocidad integrada directamente en el chip, que dicta a qué ritmo puede alimentarse el motor de cómputo) permite que TurboQuant mueva esos 3 bits a una velocidad que satura completamente el motor de cómputo, eliminando los tiempos de espera de la GPU que en generaciones anteriores anulaban parte del beneficio de la compresión.
El resultado es el salto que hace creíble el dato más impactante de esta sección: el modelo MoE de 690.000 millones de parámetros DeepSeek-V3.2 cuantizado con NVFP4 en Blackwell reduce el coste por millón de tokens desde 1 dólar en configuraciones densas hasta 0,05 dólares. Una reducción del 95% en el coste operativo que, a la escala de un despliegue empresarial, redefine completamente el análisis de viabilidad financiera de cualquier proyecto de IA generativa.
DeepSeek y MLA frente al enfoque clásico
La narrativa de DeepSeek como referente en eficiencia no es casualidad de mercado, es consecuencia de una decisión arquitectónica deliberada. Mientras la industria aplicaba cuantización como post-proceso a modelos ya entrenados, DeepSeek diseñó el problema de memoria del caché KV desde la arquitectura. Su Multi-Head Latent Attention (MLA), documentada en el DeepSeek-V3 Technical Report, comprime el caché mediante proyección de bajo rango (una técnica matemática que reduce la dimensionalidad de los datos antes de almacenarlos), con cifras reportadas de caché por token muy inferiores a las de otros modelos grandes comparables, aunque la comparación exacta depende de configuración y arquitectura.
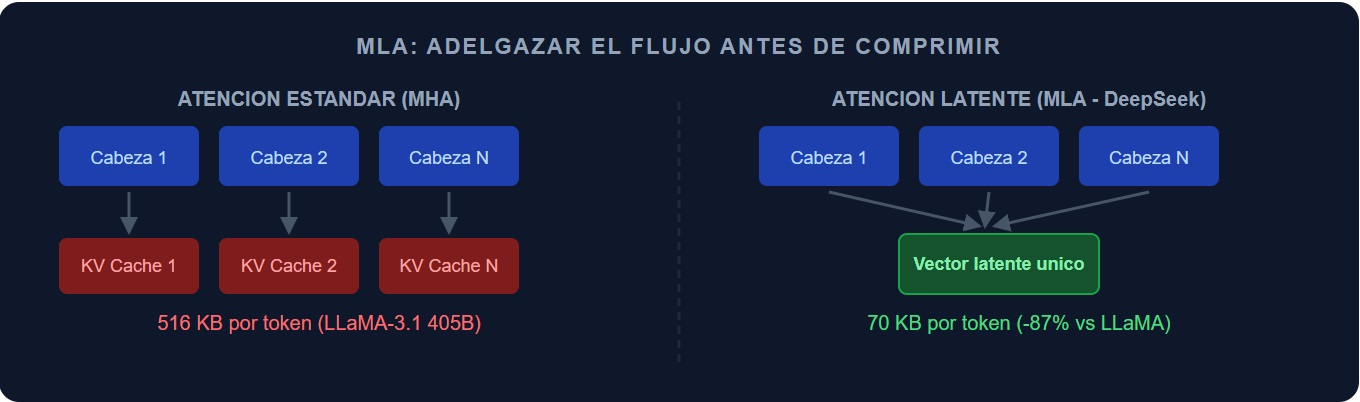
Este enfoque complementa, en lugar de competir con, TurboQuant. La lógica estratégica es clara: MLA reduce el volumen de datos que necesitan ser almacenados en el caché, y TurboQuant comprime esos datos con mayor eficiencia. Aplicados en secuencia, representan el stack de eficiencia más sólido actualmente disponible en modelos de código abierto. DeepSeek además implementa cuantización de grano fino (bloques de 128×128 para pesos y 1×128 para activaciones), permitiendo usar FP8 durante el entrenamiento y precisiones de 3 o 4 bits en despliegue con pérdidas mínimas y certificadas, lo cual reduce el riesgo de adopción frente a métodos de cuantización más agresivos y menos auditados.
Llama 4: Modelos grandes, hardware modesto
Con Llama 4, Meta reforzó una dirección que el ecosistema open weight lleva tiempo explorando: la cuantización selectiva por capas incorpora una arquitectura Mixture-of-Experts (MoE) que permite cuantización selectiva por capas. No todas las capas de un LLM tienen la misma sensibilidad a la compresión: las capas de atención y ciertas capas críticas requieren mayor precisión, mientras que las capas de expansión de expertos (ffn_exps) toleran compresiones más agresivas sin degradar el output. El trabajo de Unsloth Dynamic 2.0 GGUF, desarrollado por Daniel y Michael Han en colaboración directa con el equipo de Meta, materializa esta lógica en formatos ejecutables en hardware de consumo.

El resultado práctico: Llama 4 Scout (109.000 millones de parámetros) en versión 1,78 bits pasa de 113 GB a 33,8 GB (-75% en tamaño) y ejecuta a aproximadamente 20 tokens por segundo en una sola GPU de 24 GB de VRAM. Llama 4 Maverick (402.000 millones de parámetros) en versión 1,78 bits baja de 422 GB a 122 GB y opera en dos GPUs de 48 GB. Para organizaciones que evalúan despliegues en infraestructura propia (on-premises) o en escenarios de edge computing (procesamiento de datos directamente en el servidor local, sin enviarlos a la nube), este dato cambia radicalmente la ecuación de viabilidad bajo normativas como GDPR, NIS2 o DORA. La clave estratégica aquí es que la cuantización extrema hace posible que el modelo nunca salga del perímetro corporativo: el cumplimiento normativo se garantiza por diseño físico, no por cláusula contractual con un proveedor de nube. Es la diferencia entre confiar en un acuerdo de procesamiento de datos y no necesitar ese acuerdo en absoluto.
Todo el ecosistema descrito hasta aquí, TurboQuant, NVFP4, MLA de DeepSeek, comparte un supuesto implícito: los Transformers son la arquitectura correcta y el problema es hacerlos caber en el hardware disponible. Pero como hemos comentado hace unos días hay una voz (con acento francés) con 1.030 millones de dólares de respaldo que impugna ese supuesto de raíz.
Google: optimización de fuerza bruta
La postura de Google con TurboQuant es pragmática y tiene una lógica de negocio irrebatible a corto plazo. Los Transformers ya están en producción, ya generan ingresos y ya existen ecosistemas completos de herramientas, fine-tuning y despliegue construidos sobre ellos. Comprimir el caché KV de 40 GB a 6 GB sin pérdida de precisión no es un parche, es la diferencia entre rentabilidad y pérdida en un mercado donde la inferencia representa entre el 80% y el 90% del gasto total del ciclo de vida de la IA. El mismo razonamiento aplica a NVFP4 de NVIDIA y a MLA de DeepSeek: son respuestas de ingeniería de alta calidad a un problema de escalado definido dentro de los límites del paradigma dominante.
LeCun y AMI: el cuestionamiento estructural
Yann LeCun, Premio Turing, fundador de FAIR en Meta y ahora presidente ejecutivo de Advanced Machine Intelligence (AMI) Labs, lleva años argumentando que el problema de los LLMs no es de tamaño sino de diseño. Su tesis, desarrollada con consistencia técnica antes de que ChatGPT convirtiera los LLMs en sinónimo de IA, es que un sistema que genera el siguiente token no puede entender el mundo físico porque el mundo físico no es predecible a nivel de tokens. La energía computacional gastada «adivinando» el siguiente fragmento de texto es, en su diagnóstico, un síntoma de ineficiencia arquitectónica, no un problema que se resuelva comprimiendo mejor ese proceso. Como analizamos en profundidad en muycomputerpro.com, AMI Labs cerró en marzo de 2026 una ronda semilla de 1.030 millones de dólares a una valoración de 3.500 millones, respaldada por NVIDIA, Samsung, Toyota Ventures y Bezos Expeditions, entre otros.

La alternativa que propone LeCun es JEPA (Joint Embedding Predictive Architecture), un enfoque que no genera píxeles ni palabras sino que aprende representaciones abstractas del estado del mundo y hace predicciones en ese espacio latente (un espacio matemático interno de alta abstracción, no el espacio del lenguaje visible). El razonamiento de eficiencia es poderoso en su simplicidad: si el modelo no necesita generar información que no puede predecir con certeza, no necesita comprimir esa información ni gastar energía en producirla. La alucinación, que los LLMs actuales abordan con guardianes, filtros y costosos procesos de verificación post-generación, desaparecería por diseño. No requeriría cuantización a 3 bits de modelos de 175.000 millones de parámetros porque la arquitectura correcta operaría con una fracción de esos parámetros al no cargar con el overhead computacional de la generación token a token.
La apuesta de NVIDIA y Samsung por AMI, a primera vista contradictoria dado que ambas empresas venden chips y hardware optimizados para Transformers, responde a una lógica de seguro tecnológico calculada: si el paradigma dominante migra de Transformers a arquitecturas basadas en espacio latente como JEPA, NVIDIA quiere que los chips de la era Post-Blackwell estén diseñados para ese nuevo tipo de cómputo desde el inicio, no adaptados con parches a posteriori. Samsung, por su parte, apuesta por diversificar su exposición más allá del ciclo de memoria HBM, cuya demanda está íntegramente ligada hoy al paradigma Transformer. Invertir en AMI es, para ambas compañías, comprar opcionalidad sobre el siguiente ciclo de plataforma.
En cualquier caso muchos son los factores que juegan a favor de que la optimización para conseguir un uso de recursos más contenido por parte de la Inteligencia Artificial sea una parte fundamental a partir de ahora. Sobre todo si queremos que sea una tecnología sostenible desde el punto de vista del uso del hardware y de la energía. Y por supuesto que, cuando los costes lleguen finalmente a los usuarios tanto privados como empresariales, los precios permitan seguir escalando la adopción de la IA como herramienta fundamental para el futuro digital del mundo.








Qualcomm compra Modular por 4.000 millones para avanzar en software para IA

Cómo prepararse en criptografía post-cuántica para evitar las nuevas amenazas

Trump quiere a la IA bajo control

HPE ha construido seis de los diez superordenadores más rápidos del mundo

La IA frente al espejo

ASUS comercializa en España el mini-PC para empresas, ExpertCenter PN55

La UE presenta por fin sus planes para despegar en soberanía tecnológica

Protagonistas invisibles: la cara oculta de la inteligencia artificial

Casos de éxito de transformación digital con IA de empresas TIC y Big Tech

Anthropic suspende el acceso a sus modelos de IA, Fable 5 y Mythos 5

Cinco grandes novedades de Microsoft en la Build 2026

Inetum cierra su ERE en España con un 10% menos de trabajadores afectados
Qualcomm compra Modular por 4.000 millones para avanzar en software para IA

¿Puede Europa competir con China y Estados Unidos en la carrera tecnológica?

QNAP QSW-M7230-2X4F24T: El switch de 100 GbE para producción audiovisual e IA

¿Cómo es el portátil ideal para un directivo moderno?

La UE expulsa a EEUU de la mayoría del espectro para comunicaciones vía satélite en la región

Anaplan refuerza su plataforma con IA agéntica y nuevas aplicaciones listas para usar
-

 NoticiasHace 4 días
NoticiasHace 4 díasAccenture, en problemas: sus acciones caen hasta su valor más bajo desde 2017
-

 A FondoHace 4 días
A FondoHace 4 díasEl precio de la tecnología cliente se dispara a medida que la IA sigue acaparando chips
-

 NoticiasHace 3 días
NoticiasHace 3 díasOpenAI amplía su iniciativa de ciberseguridad Daybreak
-

 A FondoHace 4 días
A FondoHace 4 díasDe la ilusión de productividad a la UX fluida: IA y DXOP en la trinchera del empleado