Noticias
Google libera Gemma 4, su modelo de IA de código abierto más avanzado

Google ha anunciado Gemma 4, una nueva familia de modelos de IA desarrollados en la misma rama de investigación que su modelo propietario Gemini 3. Sin embargo, a diferencia de éste, la familia de modelos Gemma es de código abierto y se puede utilizar comercialmente.
Cabe destacar que, a diferencia de las versiones anteriores de los modelos Gemma, que incluían términos de uso específicos y no eran realmente de código abierto en el sentido estricto, Gemma 4 cuenta con una licencia Apache 2.0 totalmente permisiva sin restricciones comerciales. Con ello, Google desafía directamente a los modelos Llama de Meta, que también utilizan la licencia Apache.
Novedades y versiones de Gemma 4
Google ha liberado su nuevo modelo en cuatro tamaños distintos, diseñados para cubrir desde la inferencia en dispositivos móviles hasta implementaciones de clase estación de trabajo. Los cuatro modelos son multimodales, procesan vídeo e imágenes de forma nativa y están entrenados en más de 140 idiomas. «Para impulsar la próxima generación de investigaciones y productos pioneros, hemos dimensionado los modelos Gemma 4 específicamente para que funcionen y se optimicen de manera eficiente en hardware, desde miles de millones de dispositivos Android en todo el mundo hasta GPU de portátiles, pasando por estaciones de trabajo y aceleradores para desarrolladores», aseguran desde Google.
Una de las novedades más importantes de Gemma 4 es su enfoque en flujos de trabajo basados en agentes. Todos los modelos ofrecen soporte nativo para llamadas a funciones, salida JSON estructurada e instrucciones del sistema nativas. Esto permite a los desarrolladores crear agentes de IA autónomos capaces de ejecutar lógica compleja de forma fiable e interactuar con API externas, todo ello localmente.
En cuanto a rendimiento, Google asegura que el modelo Gemma 4, con una densidad de 31 bytes, ocupa actualmente el tercer puesto entre los modelos abiertos de la clasificación de Arena AI, mientras que el modelo de 26 bytes se sitúa en el sexto lugar, superando notablemente a competidores de hasta 20 veces su tamaño. Los pesos sin cuantificar de los modelos de 26 y 31 bytes caben perfectamente en una única GPU NVIDIA H100 de 80 GB.
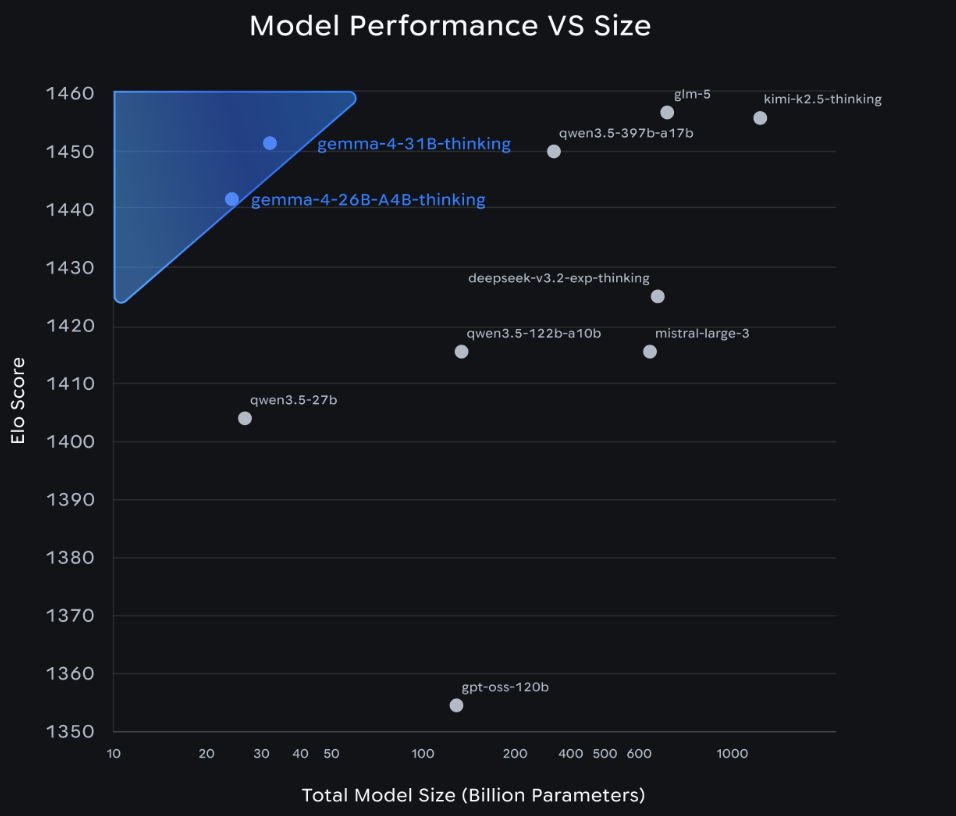
Para el desarrollo local, el modelo Mixture of Experts (MoE) de 26B está hiperoptimizado para minimizar la latencia, activando solo 3800 millones de sus parámetros durante la inferencia. Esto le permite generar tokens a una velocidad vertiginosa, lo que resulta útil para potenciar los asistentes de codificación locales en tarjetas gráficas de consumo.
Google también se ha centrado en la multimodalidad de estos modelos. Ampliando el Gemma 3n del año pasado, diseñado para dispositivos móviles , toda la familia Gemma 4 procesa de forma natural vídeo e imágenes de alta resolución. Los modelos de borde E2B y E4B van un paso más allá al incorporar entrada de audio nativa para un reconocimiento de voz fluido y con latencia casi nula. Estos modelos cuentan con una ventana de contexto de 128 KB para dispositivos de borde y de hasta 256 KB para los modelos más grandes 26B/31B.
Gemma 4 es compatible con plataformas como Hugging Face, Ollama y vLLM, además de contar con la optimización de hardware de NVIDIA, AMD, Qualcomm y MediaTek. Para los desarrolladores de aplicaciones móviles, los modelos están listos para la creación de prototipos en la versión preliminar para desarrolladores de AICore, lo que garantiza la compatibilidad con el próximo Gemini Nano 4.











¿Está preparado el comercio minorista para que los agentes de IA compren en nombre de los humanos?

La seguridad de DataAI como infraestructura fundamental para sectores críticos

Salesforce Agentic Advisor, IA agéntica para el sector financiero

Cloudflare bloqueará los rastreadores web mixtos que presten servicio a las empresas de IA

«Proporcionamos ciberseguridad de gama alta a nuestros clientes, sin importar su tamaño»

Microsoft publica los Contenedores WSL para desarrolladores

Anthropic suspende el acceso a sus modelos de IA, Fable 5 y Mythos 5

«La salud digital exige flexibilidad»

Vass prepara un ERE en España que puede afectar al 13% de sus empleados

ASUS lanza la supercomputadora de IA de escritorio, ExpertCenter Pro ET900N G3

Disponible la primera versión de Euro-Office como parte de Nextcloud Hub

La IA empresarial ya tiene un problema: las facturas
¿Está preparado el comercio minorista para que los agentes de IA compren en nombre de los humanos?

El Pentágono mantiene a Anthropic en la lista negra, pero la NSA lo utiliza en operaciones cibernéticas ofensivas

Cloudflare compra VoidZero para dar un impulso al desarrollo en la web nativa de IA

Epson renueva su gama de impresoras compactas EcoTank con cuatro nuevos modelos
La IA empresarial ya tiene un problema: las facturas

Ocho de cada diez proyectos de IA no pasan de la prueba piloto
-

 NoticiasHace 5 días
NoticiasHace 5 díasOVHcloud amplía su plataforma cuántica y profundiza la investigación en dicho campo
-

 NoticiasHace 5 días
NoticiasHace 5 díasGoogle presenta Nano Banana 2 Lite, un generador más rápido y barato
-

 NoticiasHace 6 días
NoticiasHace 6 díasEl Ministerio para la Transformación Digital y la Función Pública invierte en Openchip a través de la SETT
-

 A FondoHace 6 días
A FondoHace 6 díasMeta Vistara: hasta los centros de datos reciclan memorias para aliviar el MEMOpocalipsis