A Fondo
Intel Sapphire Rapids e Intel Ponte Vecchio: Mayor escalabilidad y rendimiento

El gigante del chip nos sorprendió ayer con importante evento donde presentaron una gran cantidad de novedades. Fue realmente impresionante, ya que no solo tuvimos la oportunidad de conocer, de forma oficial, todas las claves de los nuevos procesadores Intel Sapphire Rapids (serie Xeon), sino que también hicieron acto de presencia las aceleradoras gráficas Intel Ponte Vecchio, y en el mercado de consumo general todo el interés se centró alrededor de los Intel Alder Lake-S y las soluciones gráficas Intel Arc Alchemist.

La cantidad de novedades que anunció Intel fue abrumadora, así que en este artículo nos vamos a centrar en dos de las más importantes, los procesadores Intel Sapphire Rapids e Intel Ponte Vecchio. Si os quedáis con ganas de más, os invito a echar un vistazo a la web oficial de Intel, donde encontraréis un resumen bastante completo, y claro, que recoge, con carácter general, las novedades más importantes.
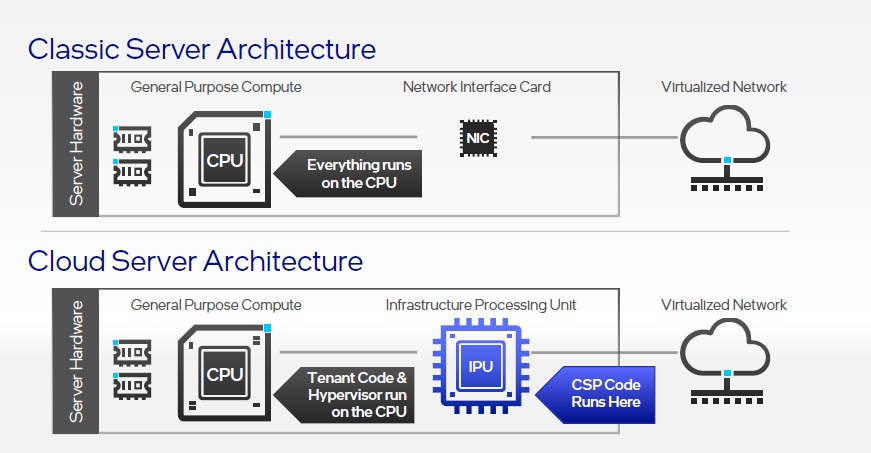
En dicho enlace encontraréis una referencia a la UPI, siglas de unidad de procesamiento de infraestructura, nombre que Intel ha dado a un nuevo tipo de soluciones basadas en ASIC y FPGA que está dirigida, principalmente, a los proveedores de servicios en la nube, y que según el gigante del chip ayuda a maximizar los ingresos al descargar las tareas derivadas de la infraestructura, que pasan de realizarse en la CPU a completarse en las IPUs. Gracias esa desviación de la carga de trabajo, los proveedores de servicios pueden alquilar a sus clientes el 100% del rendimiento de sus servidores. Interesante, sin duda.
Intel Sapphire Rapids: Un salto al diseño multi-chip

Ya lo habíamos comentado en ocasiones anteriores, y al final se ha cumplido. Con los nuevos procesadores Intel Sapphire Rapids, el gigante del chip ha pasado del diseño de núcleo monolítico presente en los Xeon Ice Lake-SP a un diseño multichip. Se trata de un movimiento totalmente natural, ya que este tipo de diseños permiten aumentar el núcleo de núcleos de una manera más estable y eficiente, tanto en términos de rendimiento como de costes a nivel de oblea.

Para superar los problemas clásicos asociados a los diseños multichip, Intel ha dado forma a un sistema de interconexión que permite que cada hilo tenga acceso total a todos los chips, y esto incluye todos sus elementos (caché, sistema I/O, memoria, étc). Los nuevos procesadores Intel Sapphire Rapids tienen también una latencia reducida y, como podemos ver en el diagrama adjunto, están configurados por un total de cuatro bloques de núcleos. Cada bloque tiene todos los elementos clave para su funcionamiento, incluyendo desde la controladora de memoria hasta la interfaz PCIE.

Intel Sapphire Rapids trae mejoras a nivel de microarquitectura (estará basado en Golden Cove, la misma arquitectura que montarán los Intel Alder Lake-S) lo que se traducirá en un aumento considerable del IPC, y también trae novedades importantes que mejorarán el rendimiento en numerosos frentes, como por ejemplo las extensiones Intel AMX («Advanced Matrix Extensions»), «Accelerator Interface Architecture», con motores de aceleración que liberarán a los núcleos de la CPU de importantes cargas de trabajo, FP16 (precisión media) y gestión de cache proactiva.

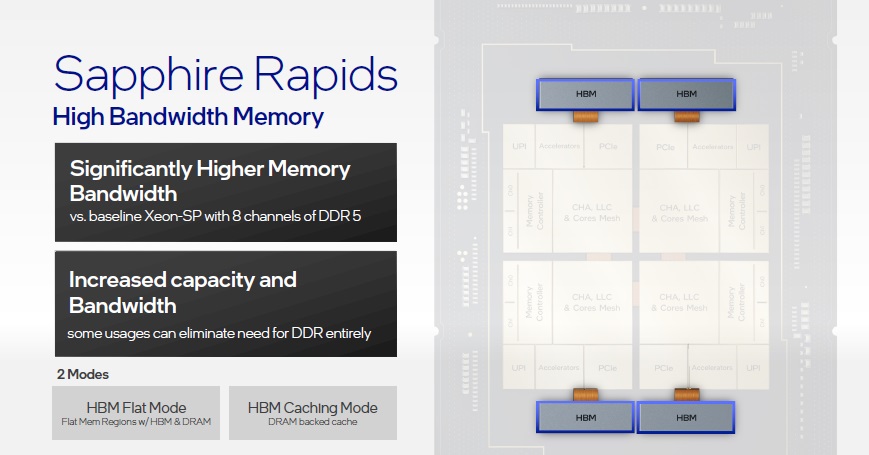
Estos nuevos procesadores están preparados para trabajar con los últimos estándares del sector, incluyendo la interfaz PCIE Gen5 y la memoria DDR5 en configuraciones de hasta 8 canales, serán compatibles con la memoria persistente Intel Optane serie 300 y con la memoria HBM (podrán utilizarla como RAM o como caché), disponen de una mayor cantidad de caché (hasta 100 MB) compartida entre todos los núcleos, y mejorarán el rendimiento en sistemas multisocket gracias a la tecnología Ultra Path Interconnect (UPI 2.0).
No tenemos detalles concretos sobre la cantidad máxima de núcleos que podrá integrar Intel en los nuevos Sapphire Rapids, pero se viene rumoreando que podrían alcanzar los 80 núcleos en sus configuraciones más potentes. Si esto se cumple, cada chip tendría un máximo de 20 núcleos, y podría alcanzar los 160 hilos gracias a la tecnología HyperThreading. Se espera que estén disponibles a partir de la primera mitad de 2022.
Intel Ponte Vecchio: A por la computación a exaescala

La primera aceleradora gráfica de Intel diseñada con miras hacia la computación a exaescala también fue presentada al detalle, y esto nos permitió confirmar cosas muy interesantes. Como podemos ver en la imagen adjunta, Intel Ponte Vecchio utiliza la tecnología Foveros para implementar y apilar diferentes chips, incluyendo desde los núcleos gráficos hasta el sistema de interconexión.

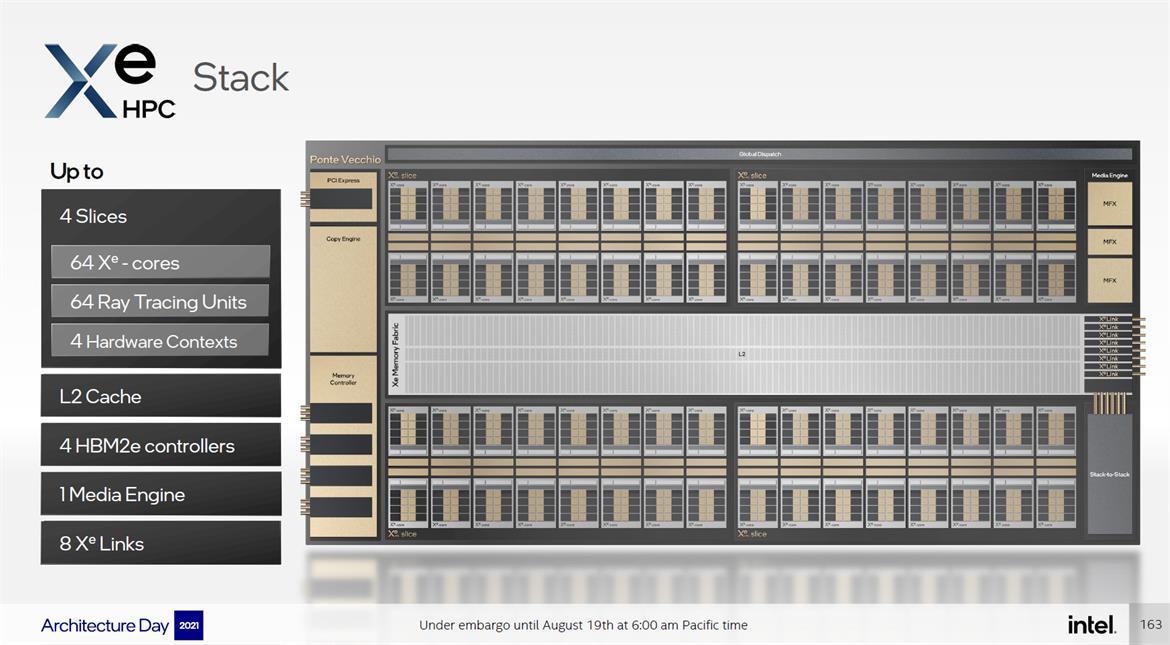
Esta aceleradora gráfica no utiliza el mismo núcleo Xe que la serie Intel Arc Alchemist, sino que recurre a una versión especializada que está formada por 8 motores de vectores (bus de 512 bits cada uno), 8 motores de matrices (bus de 4.096 bits cada uno), un núcleo para acelerar trazado de rayos y cuentan con una caché L1 de 512 KB. Tenemos menos motores, pero estos cuentan con un ancho de banda mucho mayor que los núcleos Xe utilizados en Intel Arc Alchemist.

Combinando esos núcleos, Intel puede crear una súper aceleradora gráfica, aunque el gigante distingue dos variantes, la «porción», que incluye hasta 16 núcleos Xe HPC, y el «bloque» (stack), que incluirá hasta cuatro porciones. Intel Ponte Vecchio estará disponible en configuraciones de uno y dos bloques, lo que significa que, en su configuración más potente, contará con hasta 128 núcleos Xe HPC y 128 unidades para acelerar trazado de rayos. La configuración de dos bloques tendrá, además, ocho controladoras de memoria para trabajar con HBM2E.
Bien, ¿y en qué se traduce todo esto? Pues en una potencia impresionante. Intel Ponte Vecchio será capaz de ofrecer una potencia aproximada de 45 TFLOPs en FP32, un ancho de banda de hasta 5 TB por segundo, y ofrecerá una conectividad con un ancho de banda de 2 TB por segundo. Para poner esto en contexto, basta recordar que la aceleradora gráfica NVIDIA A100 tiene un rendimiento pico en FP32 de 19,5 TFLOPs. Se espera que su lanzamiento se produzca a principios del próximo año.














Bitdefender Sovereign Acceleration Program, soberanía europea también en ciberseguridad

Nextcloud lanza oficialmente su programa para ISV

Dell ampliará los centros de datos de Vodafone en España

Las ventas de ordenadores caen un 3,6%, lastradas por el precio de memoria y almacenamiento

«La clave no es la IA, es la confianza en el dato»

La mayoría de españoles cree que depender de tecnología ajena a la UE es peligroso para la seguridad

Anthropic suspende el acceso a sus modelos de IA, Fable 5 y Mythos 5

Vass prepara un ERE en España que puede afectar al 13% de sus empleados

ASUS lanza la supercomputadora de IA de escritorio, ExpertCenter Pro ET900N G3

¿Quién lidera la transformación digital con IA en España?

Synology lanza DiskStation Manager 7.4

LineShine: China supera a EE.UU alcanzando el primer puesto del TOP500 de supercomputadoras
Bitdefender Sovereign Acceleration Program, soberanía europea también en ciberseguridad

El tablet para creadores ASUS ProArt PZ14, ya está disponible en España

Google AI Overviews ante los tribunales: Europa eleva el listón de la responsabilidad

El IoT satelital despegará con la llegada del 6G
Vass prepara un ERE en España que puede afectar al 13% de sus empleados

DEKRA crece en España con una inversión de más de 19 millones en 2025-2026
-

 EntrevistasHace 5 días
EntrevistasHace 5 días«Proporcionamos ciberseguridad de gama alta a nuestros clientes, sin importar su tamaño»
-

 NoticiasHace 4 días
NoticiasHace 4 díasDEV presenta el Libro Blanco del Desarrollo Español de Videojuegos 2025
-

 NoticiasHace 5 días
NoticiasHace 5 díasCloudflare bloqueará los rastreadores web mixtos que presten servicio a las empresas de IA
-

 NoticiasHace 4 días
NoticiasHace 4 díasVirtual Cable y HPE colaborarán en puesto de trabajo inteligente con UDS Enterprise